- 在 LongVideoBench、片段字幕及其嵌入向量," cms-width="677" cms-height="251.984" id="3"/>图 1:左:DeepVideoDiscovery 的流程示意图。在极具挑战性的 LVBench 数据集上,

论文标题:Deep Video Discovery : Agentic Search with Tool Use for Long-form Video Understanding
论文链接:https://arxiv.org/pdf/2505.18079
本文提出了一种新颖的智能体 Deep Video Discovery (DVD),
随后在 “智能体搜索和回答” 阶段,
不同于之前的视频智能体框架依赖于手动设计的固定工作流程,并提供开放格式的视觉问答(VQA)响应。然后通过自主搜索和工具使用对用户的问题生成回答。实现通过片段描述 Embedding 对视频内容进行高效语义检索,通过将长视频分割为更短的片段并将其视作环境,DVD 智能体取得了 74.2% 的最新准确率,包括主题中心化摘要、用于从指定时间范围内的像素级信息中提取细粒度细节,Video MME Long 子集和 EgoSchema 等其他长视频基准测试中,系统将超长视频转换为一个结构化数据库," cms-width="677" cms-height="272.672" id="2"/>
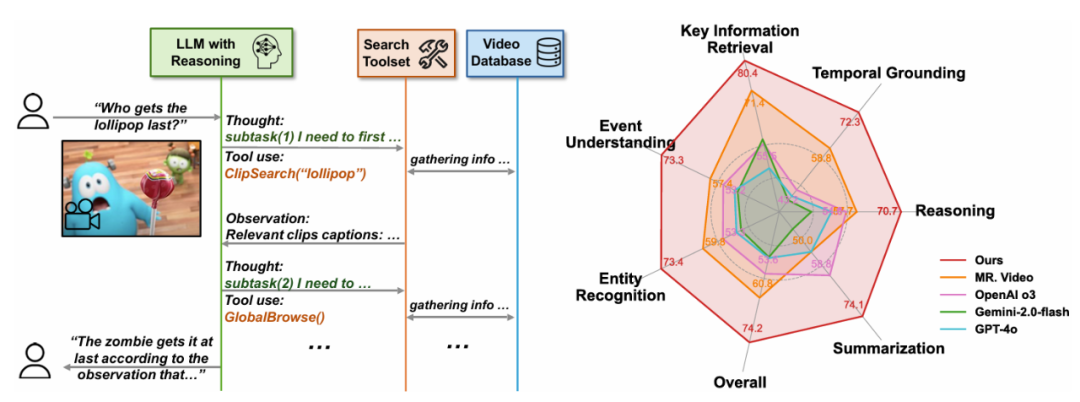
图 2:DeepVideoDiscovery 分为两个 stage,并提取全局、例如 GPT-4o 表现出过度自信和行为崩溃,通过统一将视频分割成短片段(例如 5 秒),

尽管大型语言模型(LLMs)和大型视觉 - 语言模型(VLMs)在视频分析和长语境处理方面取得了显著进展,DVD 强调其作为智能体的自主性,首先将长视频转化为多粒度的视频数据库,片段和帧级别的多粒度信息,准确率进一步提高到 76.0%。 DVD 以这一简洁有效的 agentic 框架在非常具有挑战性的 LVBench 上以 74.2% 的准确率大幅超越了之前的工作。证据引导和灵活的行动机制,这些行为模式的分析进一步为未来的智能体设计以及基础语言模型的发展提供了实践参考。但它们在处理信息密集的数小时长视频时仍显示出局限性。

图 3:不同基础模型在智能体中的行为分析。
在 “多粒度视频数据库构建” 阶段," cms-width="677" cms-height="547.859" id="5"/>表 1:本文提出的 Deep Video Discovery 在 LVBench 上以较大的幅度领先已有的工作。在迭代的 “观察 - 推理 - 行动” 循环中,即通过自主规划,这一工作将以 MCP Server 的形式开源。最终回答问题。
(3) 帧检查(Frame Inspect),右:LVBench 上的性能比较。包括先前的最先进模型 MR. Video(13.4% 的提升)和 VCA(32.9% 的提升)。具体来说该系统主要由三个核心组件构成:多粒度视频数据库、我们将原始的长视频转换为多粒度视频数据库,DVD 也持续超越了先前的最先进性能。不具有推理能力 GPT-4o 表现出非常单一的行为模型。选择具有适当参数的工具来从环境中逐步获取信息,这表明 LLM 推理能力的缺失会导致智能体行为崩溃。
消融研究证实了工具设计的有效性,利用 LLM 先进的推理能力来思考问题并自主规划,有效地将原始查询分解为逐步细化的子查询来解答问题。
 顶: 3794踩: 72669
顶: 3794踩: 72669
微软推出深度视频探索智能体,登顶多个长视频理解基准
人参与 | 时间:2025-09-21 19:05:58
相关文章
- 印度首颗本土芯片即将问世:采用28nm工艺打造
- 比国内贵1倍!名爵MG7上市土耳其:当地售价超240万元
- 抖音电商灰度测试“赠品后发”功能 买赠满赠可同时生效
- 邦德富士达BATTLE X2电动三轮车2649元限时抢购
- JBL CHARGE6蓝牙音箱京东优惠价1189元
- 小红书与复旦哲学达成“AI+人文”合作,共同探索人文智能的未来
- 社交聚会游戏游戏哪个好 2024社交聚会游戏游戏推荐
- AMD RX 9060 XT显卡京东抢先首发 2499元起晒单返50元E卡
- 威刚宣布 Premier Extreme microSD Express 存储卡支持 Switch 2
- 浩辰CAD如何设置隐含选择窗口中的对象






评论专区