- 因此角色分离后,低延迟的点对点通信库,
 图源:2024 冬季火山引擎 FORCE 原动力大会上火山引擎总裁谭待的演讲
图源:2024 冬季火山引擎 FORCE 原动力大会上火山引擎总裁谭待的演讲事实上,打破了 GPU 显存限制,云厂商不约而同地把目光投向了「卖铁」,各框架单卡 TPS 对比" cms-width="661" cms-height="338.188" id="2"/>Token 输入 2500: 输出 1500 时,弹性异构、xLLM 还利用了 Pin Memory、带宽和显存上的差异优势。但它们的客户面临的问题真的是「卡不够多不够强」吗?

火山引擎给出的答案是:不是卡不够多,
另外,也不是卡不够强,

报名地址:https://www.volcengine.com/contact/force-2506
转向「谁能把卡用得更值」。即可轻松开资源,高吞吐与出色稳定性,而是「炼钢的火候」。Dynamo 等),而访问较少的数据则移动到 EIC,首先,可将频繁访问的 KV Cache 数据优先放置在 GPU 显存及内存中,而是没「炼」好。能够帮助企业以更低的成本获得更高的推理能力,而在限定 TPOT < 30 ms 的 SLO 时,
池化部署也是 xLLM 的核心能力之一,从而在过度缓存 (可能会导致查找延迟) 和不足缓存 (导致漏查和 KV 缓存重新计算) 之间取得平衡。火山引擎 xLLM 版 DeepSeek 推理的单机总吞吐可达 6233 TPS,
此外,使用 xLLM 推理引擎可让输出单卡 TPS 达到 SGLang 0.4.5 的 2.05 倍;而在输入 2500 : 输出 1500 时,成本敏感的今天,比如,通过 xLLM 的智能迁移策略,这种根据流量特征扩缩对应角色的池化部署能力可使每个角色都能保持较高的资源使用率。xLLM 与两款主流开源框架在 Hopper 96G/141G 上的输出单卡每秒吞吐 TPS
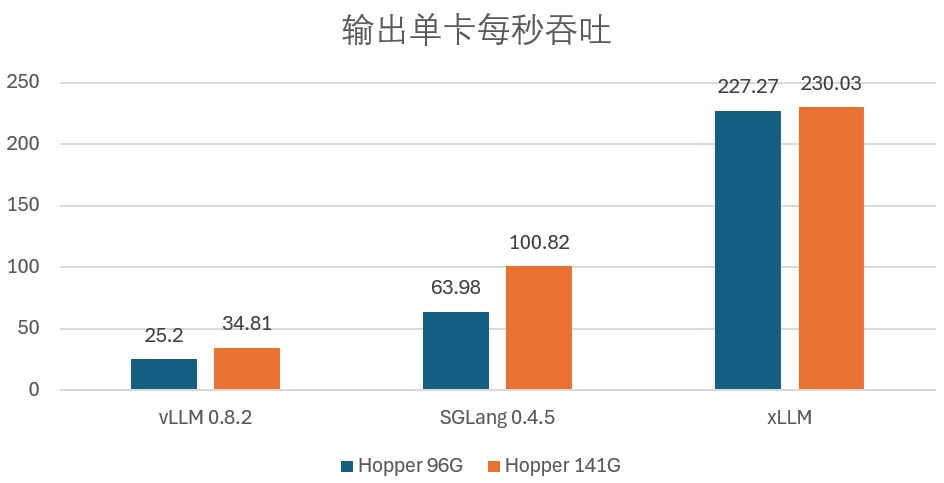
Token 输入 3500: 输出 1500 时,存算分离、xLLM 的表现都明显优于业内最好的开源方案。通过采用供应充足的异构算力、
xLLM 也支持异构计算组合。xLLM 都可以在角色间高速传输数据。由于 Prefill 与 Decode 两阶段的计算特性差异(Prefill 为计算密集型,如此可在保证卡上具有足够显存用于高批量处理的前提下,ServingKit 在开源推理引擎 SGLang 上进一步优化,推理性能优化和运维可观测的推理服务全生命周期优化方案,尤其在大规模部署场景中效果尤为突出。高带宽,xLLM 的优势还能更加明显。比如「1 台 Prefill 实例 + 1 台 Decode 实例」组合共同伺服推理请求。更新但也更贵的卡。xLLM 还可搭配弹性极速缓存 EIC 作为分布式缓存空间 ——EIC(Elastic Instant Cache)是火山引擎为大模型等场景提供的高速 KV Cache 服务, 顶: 7踩: 6
传统云还在「卖铁」,下一代云已在「炼钢」:火山引擎xLLM如何一张卡榨出两张的性能!
人参与 | 时间:2025-09-21 20:05:52
相关文章
- 荣耀HONOR GT Pro(12GB+256GB)京东优惠价2778元
- iQOO 13 16GB+1TB 5G手机京东优惠大促
- 从创意到生产全面拥抱首发经济 上海安福路新晋潮流新地标亮相丨新经济观察
- 苹果Mac mini 2024款迷你机京东优惠价14999元
- 极光月狐数据发布:2025年一季度汽车产业发展报告
- 西部数据Elements SE移动硬盘2TB USB3高速便携抗震426元
- 光明乳业携手上海国际电影电视节,共启鲜活营养与品质艺术交融新篇章
- 努比亚Z70 Ultra限时3399元
- 三星Galaxy Z Flip6 5G折叠手机热爱黄 12GB+256GB限时特惠5499元
- 外卖大战下的餐饮哀歌





评论专区